☞ 운영 체제 : Linux Ubuntu 20.04.6 LTS - focal
☞ CPU : 12th Gen Intel(R) Core(TM) i9-12900
☞ 그래픽카드 : NVIDIA GeForce RTX 2080 Ti
☞ IDE : Visual Studio Code / Python3.8 venv
목차
서버 리소스 관리나 인프라에 대해 알아보다가 Airflow를 발견하게 되었다.
현재 팀원과 함께 풋살 경기 분석 프로그램을 만들어서 테스트 서비스를 진행했었다. 이후에 업그레이드 버전을 만들 생각인데 기존 방식은 json 파일에서 작업 항목 key값을 만들고 value 값으로 boolean 타입을 받아서 실행할 작업들을 직접 선택했고, 수정할 때마다 프로그래머가 수기로 변경해야했다.
실행되는 Python 파일은 argparse 모듈을 통해 파라미터를 전달 받아서 실행했었다. 크게 번거롭지는 않았지만 경기 분석이 잦아진다면 해결해야하는 문제라고 생각한다. 그리하여 Airflow와 같이 작업 스케쥴링을 기본으로 분석 중간에 실패했을 경우에 대한 예외 처리나 재시도 로직, 모니터링, 로깅 등 데이터 파이프라인 구축 기능을 가진 툴을 학습하면 좋을 것 같다고 생각했다.
그동안 작업을 해오면서 노트에만 적고 블로그에는 기록을 못했는데 이전에 했던 것들을 정리해서 천천히 올리기도하고 다시 내가 한 것들을 기록하는 습관을 가져보려고 한다.
① Airflow
※ Airflow 란?
Airflow의 정식 명칭은 Apache Airflow라고 한다. Apache 서버나 오픈 소스의 저작권에 대해 찾아봤다면 생소한 이름은 아닐 것이다. 아파치 소프트웨어 재단(ASF)에서 개발한 소프트웨어는 보통 소프트웨어 이름 앞에 Apache를 붙이게 되는데 처음부터 ASF에서 개발한 것은 아니고 공유 숙박 플랫폼인 에어비앤비에서 초기 버전을 개발했다고 한다.
에어비앤비에서 아파치 소프트웨어 재단으로 넘어간 이후로 Airflow는 여타 오픈 소스로서 많은 개발자에 의해 발전했고, 현재 세계에서 가장 사용률이 높고 유명한 작업 스케쥴링 및 데이터 파이프라인 도구로 자리 잡았다.
자세한 내용은 docs에서 살펴볼 수 있다.
☞ Airflow docs 링크
https://airflow.apache.org/docs/
https://airflow.apache.org/docs/apache-airflow/stable/index.html
※ 설치
☞ Python 가상환경 - venv
설치는 이후에 버전 관리를 위해서 Python 3.8-venv 가상환경에서 진행했다.
가상환경이 안깔려있다면 아래와 같이 터미널에 설치하면 된다.
# python$(PYTHON_VERSION) 으로 본인의 Python 버전을 확인하고 설치하시기 바랍니다.
sudo apt install python3.8-venv
평소에 작업장으로 사용해왔던 디렉터리가 있으면 해당 경로로 이동하여 가상환경을 만들어준다.
python3 -m venv airflow
cd airflow
source bin/activate
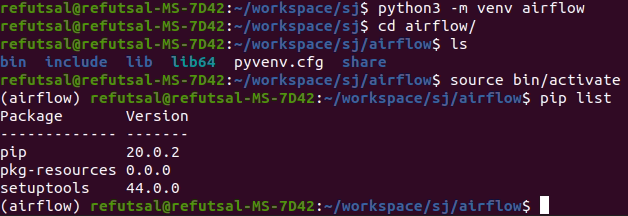
pip list를 했을 때 출력되는 내용은 기존 local에서 했던 pip list 출력과는 다르다 보통 site-packages 하위에 있는 모듈들을 출력해오는데 이전에 local에 있는 내용을 모두 불러와서 고생한적이 있었다.
1. .bashrc 파일이나 환경변수로 PYTHONPATH와 같은 내용이 선언된 것을 없애준다.
2. 재설치 -> 재부팅한다
3. 안되면 우분투를 재설치...
이렇게 해서 해결했던 것으로 기억한다.
☞ 의존성 패키지 설치 & 환경변수 설정
sudo apt update -y && sudo apt install -y python3-pip libmysqlclient-dev libssl-dev libffi-dev libxml2-dev libxslt1-dev zlib1g-dev
sudo apt upgrade -y
설치 방법은 매우 간단한 편이다. 터미널을 열어서 의존성 패키지를 설치해준다.
Airflow는 Python 언어로 개발되어 Python 패키지 관리자인 pip로 모듈을 다운받기때문에 필수적으로 필요하고 이외에도 SQL이나 암호화 프로토콜 등 의존성 패키지들이 필요하다.
Airflow docs의 Quick start 파트를 보면 선택사항이긴 하나 처음에 경로와 버전을 설정해주고 다운로드를 한다.
export AIRFLOW_HOME=~/airflow
AIRFLOW_VERSION=2.8.0
PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
터미널에서 즉석으로 입력하는 경우 다른 터미널을 실행했을 때 소싱이 되지 않기 때문에 AIRFLOW_HOME 변수의 경우 홈 디렉터리에 있는 bashrc에 입력하고 소싱해주는 것이 좋다.
# 편집기 -> nano, vi, gedit 등 원하는 것을 사용하여 편집
sudo gedit ~/.bashrc
# 편집기에 저장하기
AIRFLOW_HOME=~/airflow
# 편집기에 저장한 후 터미널에서 소싱 명령
source ~/.bashrc
위와 같이 터미널에 입력하면 되는데 PYTHON_VERSION 환경변수를 설정할 때 2버전의 값이 출력된다면 3버전에 대한 버전 값을 출력하도록 만들어주면 된다.
# 본인의 Python 버전이 3.8.10인 경우의 출력 -> 3.8
export PYTHON_VERSION=$(pkg-config --modversion python3)
# 출력 방법
echo $PYTHON_VERSION
pkg-config는 해당 운영체제에서 설치한 패키지의 버전이나 라이브러리 경로 등을 출력한다. 초기에 설치되는 패키지의 경우 pkg-config의 .pc 확장자로 저장되므로 위와 같이 버전을 출력할 때도 사용할 수 있다.
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
의존성 패키지 설치와 경로 설정을 완료하면 pip를 통해 airflow를 설치한다. 설치가 완료되면 pip list | grep airflow 명령어로 다음과 같은 내용을 얻을 수 있다.(airflow 부분만 디스플레이가 일그러져 화가 잔뜩 났다)

※ Airflow 웹 서버 접속하기
☞ DB init & port 접속
Airflow docs의 Quick Start 내용에 의하면 standalone으로 사용하는 것은 제품에 사용하는 것이 아니라 개발 목적으로만 사용하는 것이 바람직하다고 한다.
개발 목적인 경우 standalone으로 사용하고 제품에 직접적으로 사용하는 것은 하지말라고 한다. 이 내용은 이후에 실제로 개발을 하다보면 느끼게 되지 않을까.
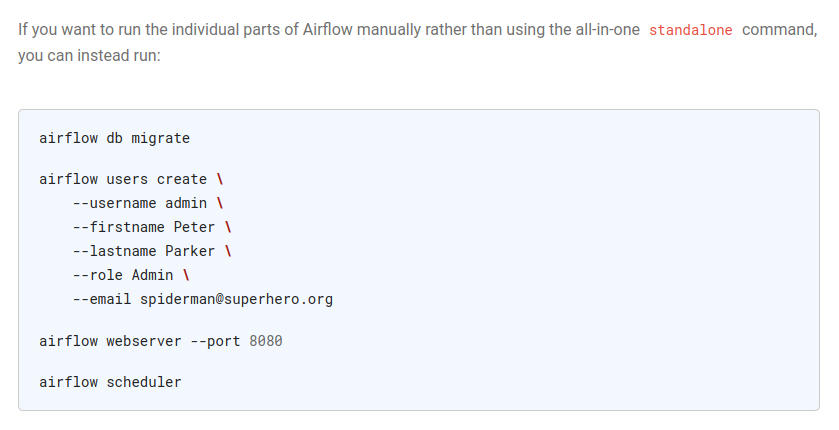
개별적으로 airflow의 기능을 실행할 경우 한 번에 전부를 실행해버리는 standalone 명령어를 사용하지말고 위와 같이 입력하여 사용하라고 한다. 무튼 시키는 대로 DB 사용자를 추가해주자. 그리고 나서는 사용자 정보를 바탕으로 실행하면 된다.
airflow db migrate
airflow users create --username yasun95 --firstname yaho --lastname sunjong --role Admin --email sjyoo9210@gmail.com
airflow webserver --port 8080
airflow db migrate를 입력한 경우에는 Databases migrating done! 이라는 문구가 나오지만 몇 경고들이 쏟아져 나오는데.....이런 것들은 초기에 해결해야하는게 좋다...
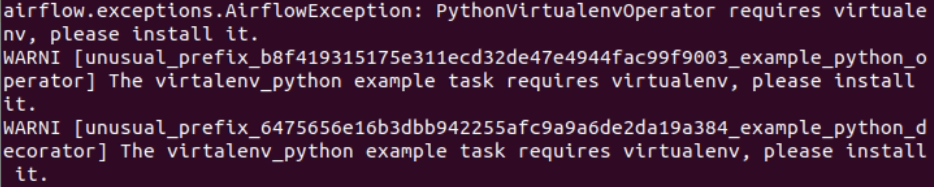
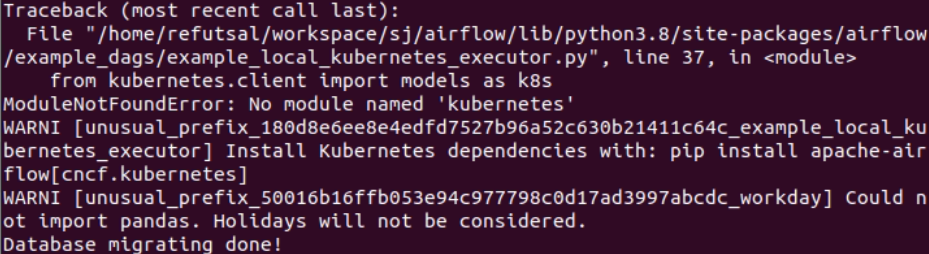

다행히도 간단한 해결책이 있다. 상단의 내용은 Airflow에서 제공하는 virtualenv_python 예제에는 virtualenv 모듈이 필요하다고 설치를 하라고 한다. 저 예제를 해볼지는 모르겠지만 일단 경고문이 나왔으니 설치해주는게 좋다.
하단의 내용은 kubernetes 라는 모듈이 없다는 에러입니다. 이것도 설치해주면 경고문이 사라진다.
pip install virtualenv kubernetes apache.airflow.providers.cncf.kubernetes
standalone 으로 실행하는 경우
잠시 standalone에 대해 얘기해보자면 이는 리눅스 운영체제의 데몬 서비스 방식 중 하나인데 inetd와 standalone 방식 두 가지로 설명한다. inetd 방식은 슈퍼 데몬(서버)이라 불리우는 xinetd의 요청에 따라 클라이언트가 필요로 하는 경우에 동적으로 서비스되는 방식이고 standalone은 부팅 후 상시 메모리(백그라운드)에 대기하여 요청이 들어오는 즉시 서비스할 수 있도록 하는 독립된 프로세스이다. 상시 메모리에 대기하는 만큼 엄청난 메모리를 요구하는 작업은 없으나(최적화도 되어있고) 메모리의 일부를 계속 사용하기 때문에 캐싱과 같이 메모리를 사용하더라도 성능을 향상할 수 있는 용도로 사용된다.
standalone 실행은 아래의 명령으로 할 수 있다.
airflow standalone
airflow standalone을 입력한 경우에는 다음과 같은 문구가 출력된다.

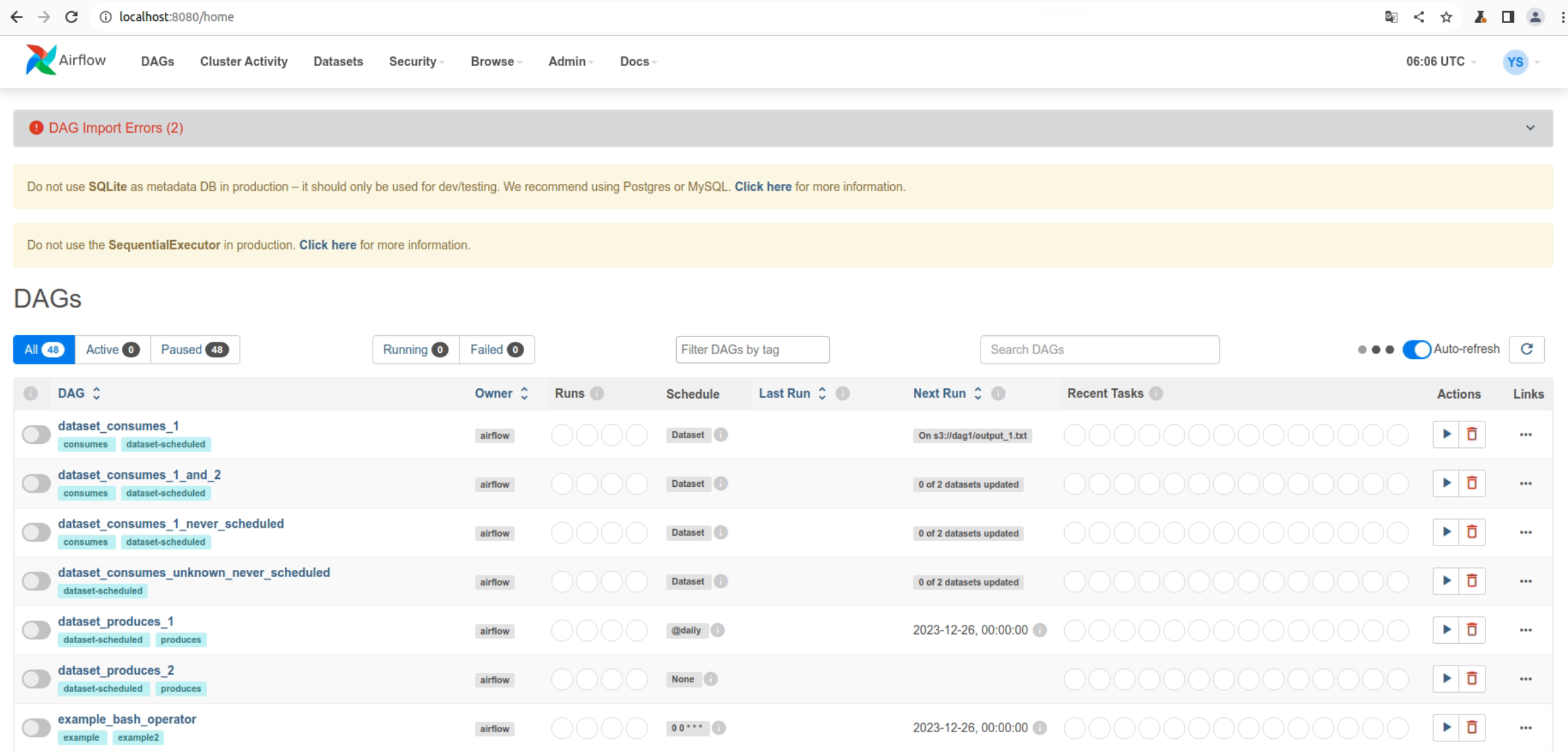
이제 브라우저 주소창에 http://localhost:8080를 입력하여 접속하면 Airflow의 홈을 확인할 수 있다. 가장 윗부분을 보면 DB에 대한 내용이 나와있다.
예제 DAG 제거 방법
접속하면 위와 같이 초기 예제와 함께 경고 문구들을 확인할 수 있다. 예제를 제거하려면 환경설정 파일에 load_example 변수를 False로 설정하면 된다.
# 터미널에서 편집기 명령과 함께 Airflow의 환경설정 파일을 열어 load_examples = False로 변경하자
gedit ~/airflow/airflow.cfg
# DB 파일을 삭제해준 후 다시 DB 초기화로 파일을 생성해준다.
rm -rf ~/airflow/airflow.db
airflow db init

다만, db init을 하면 이전에 등록했던 사용자의 정보도 없어지니 참고 바람바람

또한 Airflow는 SQLite가 아닌 Postgres나 MySQL 사용을 추천하고 있다. docs를 살펴보면 다음과 같은 문구가 있다.

SQLite의 사용을 추천하지 않는 이유는 병렬화가 불가능하기 때문이란다. 다행히 나는 SQLite로 개발하고 있지 않다! 하지마라는 것은 안 하는게 가장 좋다ㅎ_ㅎ 그래서 추천대로 MySQL을 사용해보자.
☞ Redis 설치
airflow db migrate 명령을 실행하고 DB 사용자를 생성하면 다음과 같은 경고문을 볼 수 있다.

Flask를 사용하는데 있어서 요청 속도(제한된)와 같은 내용을 저장하더라도 내부 메모리는 재부팅 시 이전 데이터에 대한 손실을 가져오므로 외부 스토리지를 만들어 저장하라고 한다. Redis(REmote DIctionary Server)는 이러한 문제를 해결해주는 데이터베이스 인 것 같다. 아래의 링크에 접속하면 매우 자세한 Redis 소개 및 정리글을 읽을 수 있다.
Redis를 통해 복잡한 Query를 단순하게(key-value 형식) 바꿔 쉽고 빠르게 DB에 접근할 수 있다고 한다.
sudo apt install redis-server
pip install connexion[swagger-ui]
# bashrc에 swagger 경로 설정하기
# 먼저 터미널에서 편집기를 실행
sudo gedit ~/.bashrc
# 편집기에 작성
export swagger_path=~/refutsal/.local/lib/python3.8/site-packages/swagger_ui_bundle
터미널에 Redis 서버 설치 명령과 함께 swagger-ui를 설치하고 swagger_path라는 환경변수를 만들어 경로 설정을 해주면 이미지 하단의 경고문을 다시 보지 않을 수 있다.
pip list | grep swagger
pip show swagger_ui_bundle
swagger의 경로는 다를 수 있고 모르는 경우 터미널에 위와 같이 swagger의 모듈명을 알아낸 후에 show 명령어를 통해 모듈의 경로를 알아내면 된다.
☞ requirements.txt
적당히 설치를 다 한 것 같으니 reuirements.txt 파일을 만들어 현재 venv에서 설치한 모듈의 정보를 기록하자.
pip freeze > requirements.txt
② DAG 생성 & 실행하기
Python 코드를 작성하여 스케쥴을 만들기까지 작업들은 모두 완료해주었다. 이제 예제 코드를 참고하여 airflow의 기능을 사용해보도록 하자.
# 웹 서버 실행
airflow webserver --port 8080
웹 서버를 실행하면 http://localhost:8080에서 airflow UI를 사용할 수 있게됩니다.
※ DAG 생성하기
☞ DAG란?
DAG는 Directed Acyclic Graphs의 약어로 방향성 비순환 그래프를 의미하며, Airflow에서 작업(task)의 흐름을 나타내는데 사용한다. 의미와 같이 방향이 존재하는데 순환하지 않는 그래프이다. 웹 서버 실행 후 UI에서 Graph 항목을 클릭하면 다음과 같이 확인할 수 있다.
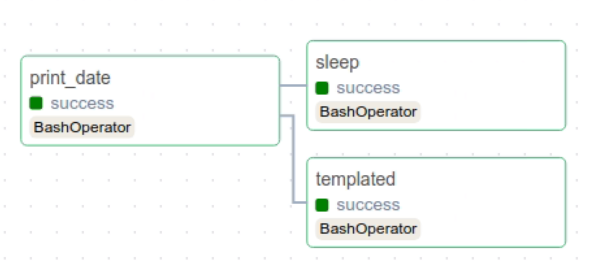
다른 예제들을 지우고면 웹 서버에서는 tutorial DAG 하나만 남겨져있는 것을 확인할 수 있는데 새로이 DAG를 생성해보기 위해서 3개의 task를 만들고 각각 10씩 숫자를 세는 DAG를 만들어보자.
소스코드 파일 생성은 airflow/dags 안에 해주어야 airflow.cfg가 DAG 생성을 확인할 수 있다. 폴더를 만들어 하위 디렉터리에 소스코드 파일을 만드는 것은 상관없다.
☞ 소스 코드(count.py)
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
"owner": "airflow",
"depends_on_past": False,
"email": ["airflow@example.com"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
}
with DAG(
"number_counting_dag",
default_args=default_args,
description="A simple DAG to count numbers",
schedule_interval=timedelta(days=1),
start_date=datetime(2024, 2, 12),
catchup=False,
tags=["example"],
) as dag:
count_10 = BashOperator(
task_id="count_10",
bash_command="for i in {1..10}; do echo $i; sleep 1; done",
)
count_20 = BashOperator(
task_id="count_20",
bash_command="for i in {11..20}; do echo $i; sleep 1; done",
)
count_30 = BashOperator(
task_id="count_30",
bash_command="for i in {21..30}; do echo $i; sleep 1; done",
)
count_10 >> count_20 >> count_30
코드 설명 보기
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
먼저, 날짜 및 시간 관련 기능을 제공하는 모듈, airflow에서 Bash 명령을 실행할 수 있도록 도와주는 모듈을 불러온다.
default_args = {
"owner": "airflow",
"depends_on_past": False,
"email": ["airflow@example.com"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
}
DAG에 파라미터로 들어갈 기본 값을 설정해줍니다. 여기서 DAG의 소유자, 이전 task에 대한 의존성, 작성자 정보, 작업 실패시 재시도 수, 간격 등을 설정할 수 있다.
with DAG(
"number_counting_dag",
default_args=default_args,
description="A simple DAG to count numbers",
schedule_interval=timedelta(days=1),
start_date=datetime(2024, 2, 12),
catchup=False,
tags=["example"],
) as dag:
DAG를 생성하며 그에 대한 정보들을 입력할 수 있다.
- "number_counting_dag" : DAG ID 설정
- default_args=default_args : 앞서 작성한 DAG 초기값 설정
- description="A simple DAG to count numbers" : DAG에 대한 설명
- chedule_interval=timedelta(days=1) : DAG의 실행 주기 (이 경우에는 매일 실행)
- start_date=datetime(2024, 2, 12) : DAG의 실행 날짜 설정
- catchup=False : 이전 실행을 추적할지에 대한 여부, default_args의 "depends_on_past", BashOperator 클래스의 wait_for_downstream과 함께 이전 task에 대한 의존성을 통해 task를 예외 상태가 발생했을 경우 task 실행에 대한 척도가 된다.
- tags=["count_example"] : 태그 설정(아래 이미지 참고)

count_10 = BashOperator(
task_id="count_10",
bash_command="for i in {1..10}; do echo $i; sleep 1; done",
)
count_20 = BashOperator(
task_id="count_20",
bash_command="for i in {11..20}; do echo $i; sleep 1; done",
)
count_30 = BashOperator(
task_id="count_30",
bash_command="for i in {21..30}; do echo $i; sleep 1; done",
)
각 작업은 count_10, count_20, count_30의 이름으로 1부터 10, 11~20, 21~30까지 숫자를 출력하고 1초씩 sleep한다.
count_10 >> count_20 >> count_30
이는 작업간 의존성을 설정한다. 작업은 count_10, count_20, count_30 순으로 앞선 작업이 성공적으로 완료되고 다음 작업이 실행하는 구조이다. 만약, 이전 작업이 실패했을 경우 다음 작업은 진행되지 않는다.
만약 이전 작업의 성공 여부와 상관없이 다음 작업을 실행하게 하고 싶다면 BashOperator안에 depends_on_past=True를 적어주면 된다.
나는 airflow/dags 안에 example이라는 폴더를 하나 만들어서 하위 디렉터리에 소스코드 파일을 저장하였다.
tree를 출력해보면 디렉터리 구성은 다음과 같다.
├── example
│ ├── __pycache__
│ │ └── count.cpython-38.pyc
│ └── count.py
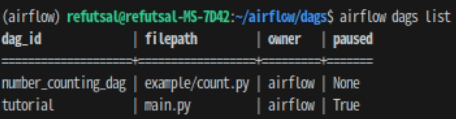
그리고 나서 터미널에 dag 리스트 출력 명령어를 입력해보면 다음과 같다.
# 데이터베이스 테이블 초기화
airflow db migrate
# 활성화한 DAGs 리스트 출력
airflow dags list
# numbering_counting_dag 작업 리스트 출력
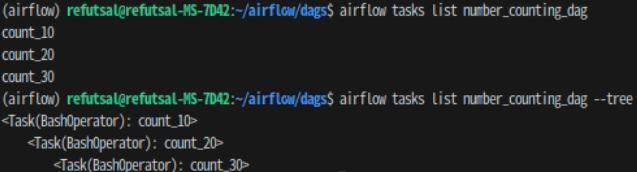
airflow tasks list number_counting_dag
# numbering_counting_dag 작업 트리 출력
airflow tasks list number_counting_dag --tree
※ DAG 실행하기
☞ DAG 테스트
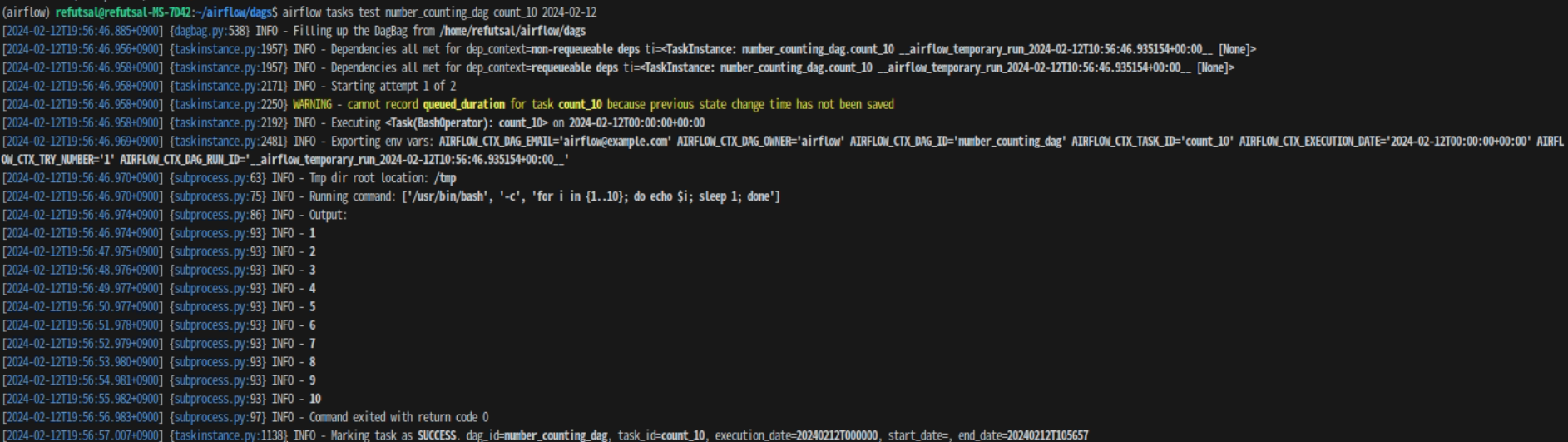
airflow tasks test number_counting_dag count_10 2024-02-12
작업 count_10을 테스트하면 결과는 다음과 같다.
☞ DAG 실행 - 웹 서버
터미널에 스케줄러를 실행해준다. (웹 서버를 시작하지 않았다면 같이 해준다.)
# 웹 서버 시작
airflow webserver --port 8080
# 스케줄러 시작
airflow scheduler
그러면 이전에는 tutorial 밖에 없던 웹 서버 UI에 "number_counting_dag"라는 이름의 DAG가 생긴 것을 확인할 수 있다.
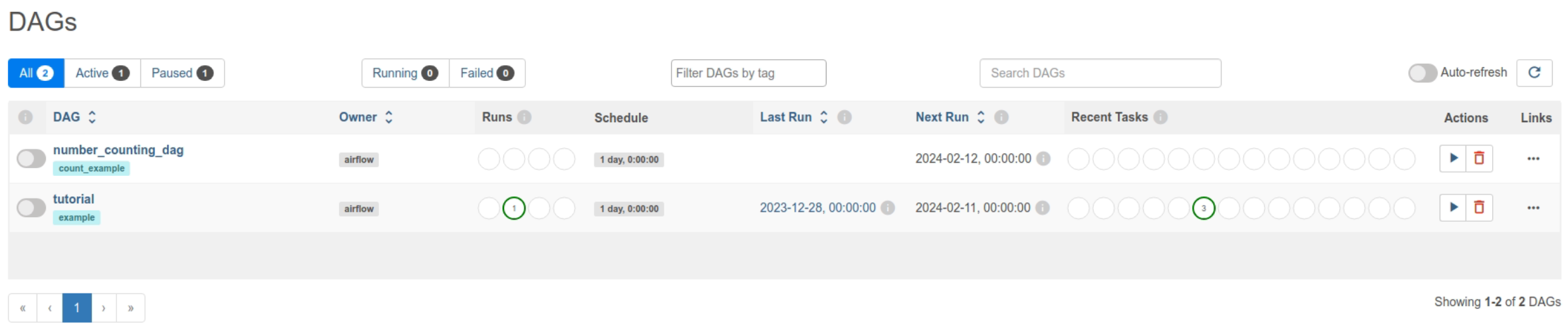
Graph에 들어가면 작업 트리를 확인할 수 있다.

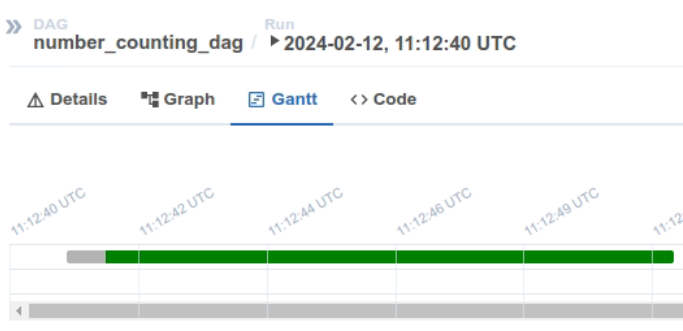
아직 실행하지 않아서 무색으로 되어있다. 웹 서버의 우측을 보면 Trigger DAG 버튼(재생 아이콘)이있다 이것을 클릭하면 DAG를 실행할 수 있다. 실행하고 나면 잠시후 달라진 그래프와 간트 차트를 확인할 수 있다.

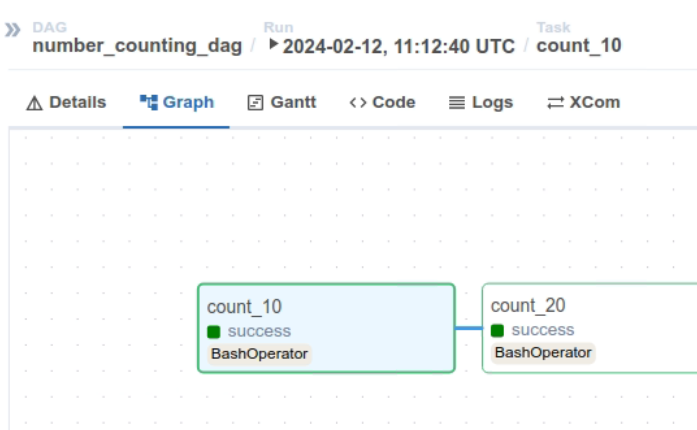
그리고 여기서 특정 작업을 선택하면 툴바에 Logs가 보이게 되는데 해당 작업의 실행 로그를 확인할 수 있다.
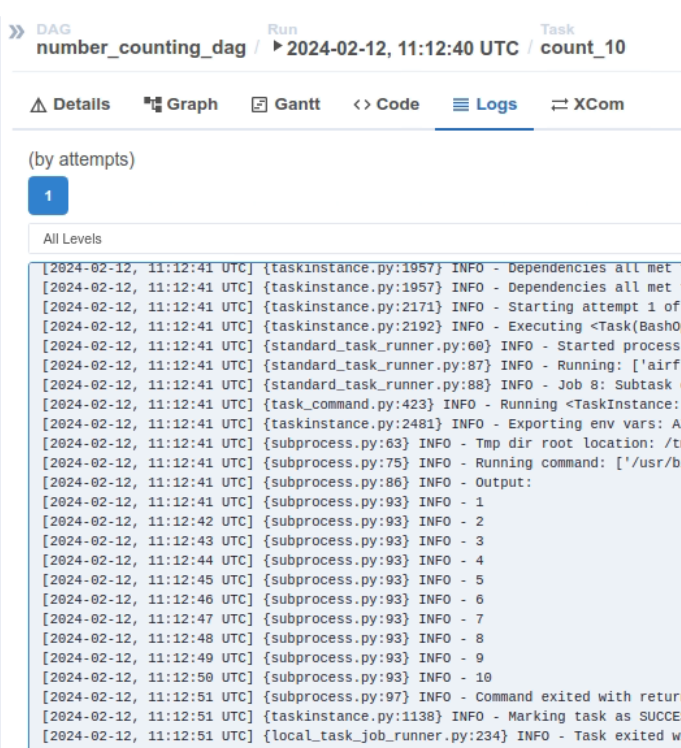
count_20, count_30도 마찬가지로 클릭하면 Log를 확인할 수 있다. 모두 성공적으로 출력된 것을 확인할 수 있다.
☞ DAG 실행 - CLI(터미널)
만약 웹 서버 UI가 아닌 터미널을 통해 DAG를 활성화하려면 아래와 같이 터미널에 입력해주자.
airflow dags unpause number_counting_dag


그리고 trigger DAG 버튼을 누르는 것과 동일한 명령을 하려면 다음과 같이 작성하면 된다.
airflow dags trigger --conf '{"key":"value"}' number_counting_dag

특정 작업을 선택하여 실행하고 싶다면?
# 특정 작업 실행하기
airflow tasks run number_counting_dag count_10 2024-02-12T11:23:33+00:00

해당 작업의 시작 시간을 입력해주어야해서 비효율적인 것 같다...아니면 다른 방법이 있다던지...
각 작업의 로그를 확인하고 싶다면?
방법이 없다ㅎ.ㅎ
CLI보다는 UI로 관리하는 것이 좋아보인다.(아직은..?)
아직 사용해보지못한 CLI 명령어와 UI 기능들이 있다. 이를 사용하다보면 이후에 개발된 소스코드들의 파이프라인을 만들 때 시간을 많이 단축하고 잘 관리할 수 있을 것이라 기대된다.